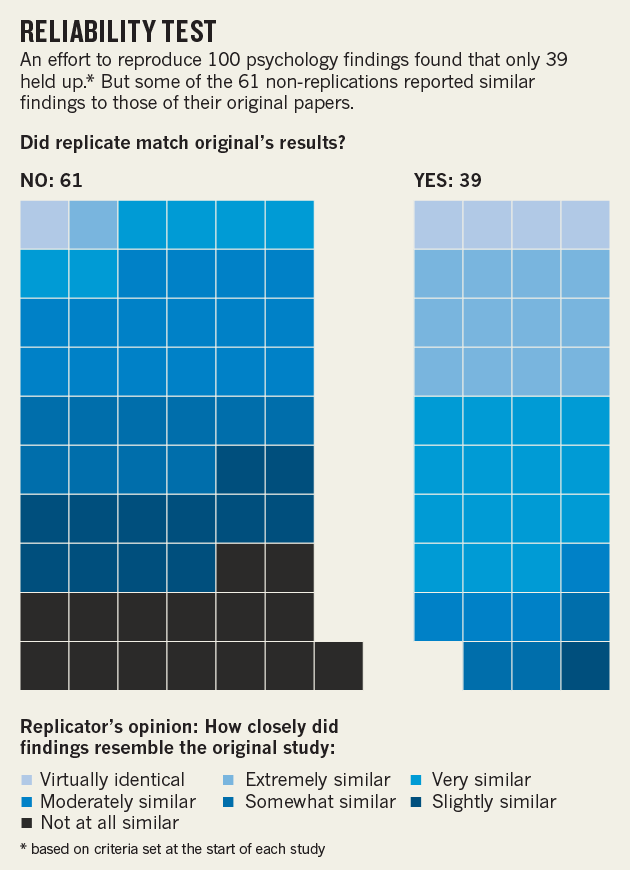
The new year began with good news: our Laboratory, together with the Cognitive Research Laboratory of the RANEPA, won the RFBR grant to study the replicability of experiments in the field of cognitive psychology using virtual reality technologies. This study is carried out in the context of the replication crisis in modern psychology: according to […]
Arizona Sunshine and the Question of Monomodality
Over the course of the project, a number of dedicated topics worthy of separate research have emerged. Each of these topics, given enough data-analysis, literature reviews and, most importantly, conceptual work, would be candidates for publications. I would like to use this space to talk about some of these ideas in their outlines, and as […]
Our available VR titles

I’ve decided to finally do a write-up of the current social virtual reality applications we have available for research. We’re constantly looking for new social spaces, so feel free to message us with suggestions. The core requirements are: There must be a multiplayer (preferably cooperative) element to the VR interaction There must be a reasonably […]
On the Multimodal Accomplishment of an Ambiguous Multi-step Action in Virtual Reality.

Foreword The following post is intended to be the first of many methodological/experiential ruminations about researching specific VR-related phenomena. Most of the terminology employed will be adapted from key microsociological works in related areas. For a primer, see Suchman (1987) and Goodwin (2017), along with Sacks (1995). All of the posts are meant to be […]